
pytorch는 numpy와 매우 비슷하며 호환성이 높다.
t = torch.FloatTensor([0., 1., 2., 3., 4., 5., 6.])
print(t)
FloatTensor라는 함수를 사용하여 float형 1차원 배열을 tensor로 표현.
GPU 사용하려면 torch.cuda.FloatTensor 함수 사용하면 되는데 나는 도대체 왜 cuda 오류가 나는건지....

언젠가 cuda와의 싸움에서 승리하고 말겠음...........
중요한건 꺾이지 않는 마음이지.. 그치..
나도 GPU 쓰고싶단 말이다.. !
어쨌든 본론으로 돌아와서
print(t.dim())
print(t.size())
print(t.shape)
print(t[2:5], t[-1], t[:4])
#################output#####################
1
torch.Size([7])
torch.Size([7])
tensor([2., 3., 4.]) tensor(6.) tensor([0., 1., 2., 3.])
보다시피 numpy와 함수들도 매우 비슷함. 2D array에 대해서도 동일하게 적용.
https://pytorch.org/docs/stable/tensors.html
BroadCasting
다른 차원의 벡터 연산을 수행할 때 자동적으로 size 맞춰서 연산을 수행.

Multiplication vs Matrix Multiplication
사용자 입장에서 주의해서 사용해야함.
why?) 사이즈가 같은 두 tensor끼리 연산을 수행해야 하는데, 실수로 다른 사이즈의 텐서끼리 계산이 되었다고 하자. 원래 같으면 에러가 떠서 우리가 바로 프로그램의 잘못된 부분을 쉽게 찾을 수 있지만 pytorch는 아무 에러를 보여주지 않고 자동적인 broadcasting 통해서 연산을 수행한다. 따라서 사용자는 프로그램이 에러 없이 종료 되었을 때 프로그램에서 잘못된 부분을 찾기 어렵다.
1. Multiplication : 일반적인 곱셈의 경우 사이즈가 같아야하는데, 아래의 예시에서는 m1과 m2의 size가 다르다. 따라서 브로드캐스팅을 통해서 사이즈를 맞춰준다. 그리고 나서 기존의 element wise한 연산을 수행
m1 = torch.FloatTensor([[1,2], [3,4]])
m2 = torch.FloatTensor([[1], [2]])
print(m1.shape) #2x2
print(m2.shape) #2x1
print(m1*m2) #2x2
print(m1.mul(m2))
#################output#####################
torch.Size([2, 2])
torch.Size([2, 1])
tensor([[1., 2.],
[6., 8.]])
tensor([[1., 2.],
[6., 8.]])
2. Matrix Multiplication : 행렬 곱, inner product 연산 수행
m1 = torch.FloatTensor([[1,2], [3,4]])
m2 = torch.FloatTensor([[1], [2]])
print(m1.shape) #2x2
print(m2.shape) #2x1
print(m1.matmul(m2)) #2x1
#################output#####################
torch.Size([2, 2])
torch.Size([2, 1])
tensor([[ 5.],
[11.]])
Mean : t.mean()
정수형 데이터 타입에서는 mean 함수 사용 불가함. 아래 예시를 보자.
#Can't use mean() on integer dtype
t = torch.LongTensor([1,2])
try:
print(t.mean())
except Exception as exc:
print(exc)
#################output#####################
mean(): could not infer output dtype. Input dtype must be either a floating point or complex dtype. Got: Long
그리고, Can also use t.mean by higher rank tensors to get mean of all elements, or mean by particular dimension.
t = torch.FloatTensor([[1,2], [3,4]])
print(t)
#################output#####################
tensor([[1., 2.],
[3., 4.]])print(t.mean())
print(t.mean(dim=0)) #0차원을(1번째 차원) 삭제한다고 생각하믄 됨. (2x2) -> (1x2) = (2, )
print(t.mean(dim=1)) #얘는 두번째 차원 삭제한다고 생각. (2x2) -> (2,1)
print(t.mean(dim=-1))
#################output#####################
tensor(2.5000)
tensor([2., 3.])
tensor([1.5000, 3.5000])
tensor([1.5000, 3.5000])
Max & Argmax : t.max() & t.argmax()
The max operator returns 2 values when called with dimension specified. The first value is the maximum value, and the second value is the argmax, the index of the element with maximumn value.
max : 말 그대로 max값 반환
argmax : input tensor에 있는 모든 element들 중에서 가장 큰 값을 가지는 공간의 인덱스 번호를 반환
print(t.max(dim=0))
print("max: ", t.max(dim=0)[0])
print("argmax: ", t.max(dim=0)[1])
#################output#####################
torch.return_types.max(
values=tensor([3., 4.]),
indices=tensor([1, 1]))
max: tensor([3., 4.])
argmax: tensor([1, 1])
t.max(dim=0)은 max와 argmax 두 값을 반환하므로 각각의 값을 얻고 싶다면 인덱싱 해주면 됨.
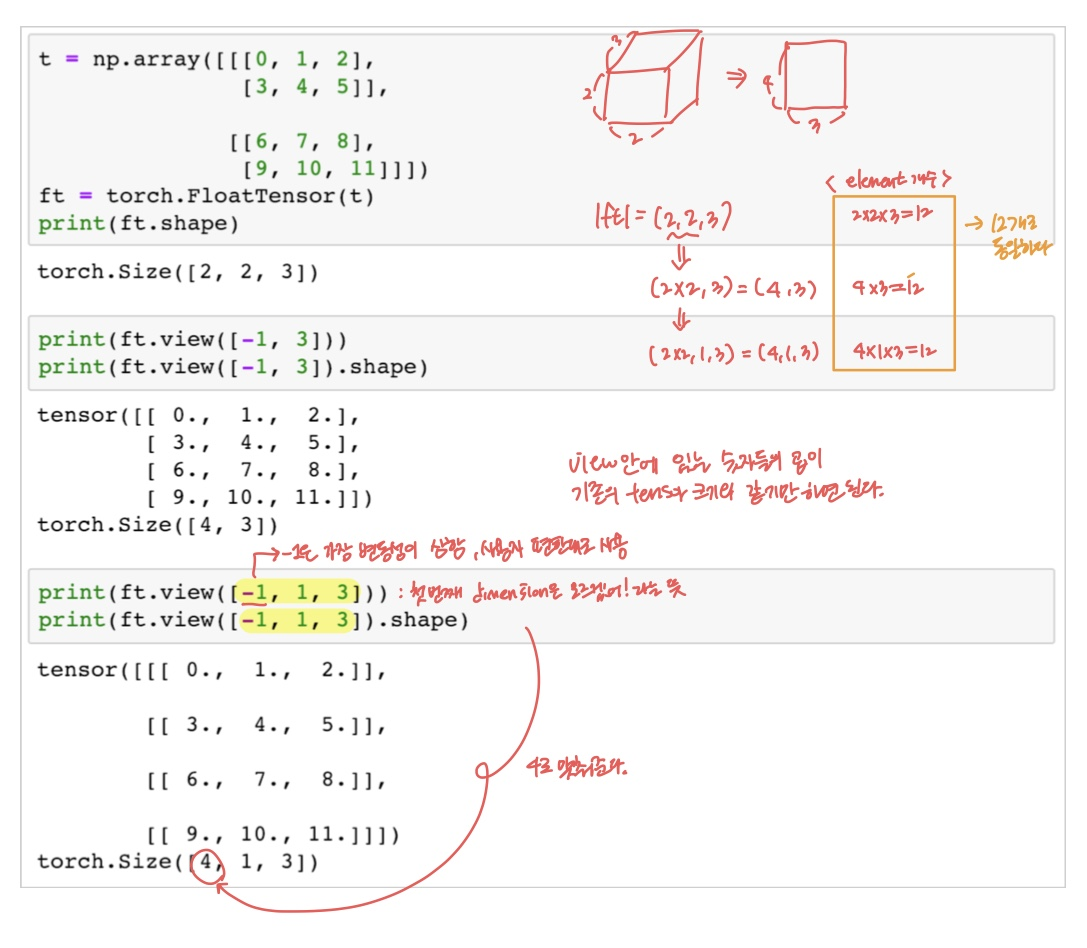
View(Reshape) : t.view()
view 함수를 사용해서 원하는 형태로 tensor를 자유자재로 변형할 수 있다. 중요함!!!
요소(element)의 갯수는 당연히 변하지 않음. 만약 변한다면... 이 함수를 쓰는 의미가 없을 것이다ㅋㅋ
딥러닝 코딩에서 매우 중요한 부분임!
Squeeze : t.squeeze()
말 그대로 쥐어짜자!!! 바로 위의 view 함수와 매우 유사하지만 squeeze는 자동으로 원하는 dimension 혹은 전체에서 dimension에 남아있는 element의 갯수가 1인 경우에 그 dimension을 삭제해준다.
예시를 보자!
ft = torch.FloatTensor([[0], [1], [2]])
print(ft)
print(ft.shape)
##################output###################
tensor([[0.],
[1.],
[2.]])
torch.Size([3, 1])
이 텐서의 size의 값은 | ft | = (3,1) 이다.
print(ft.squeeze())
print(ft.squeeze().shape)
##################output###################
tensor([0., 1., 2.])
torch.Size([3])
여기서 squeeze를 사용하면 | ft | = (3, )으로 바뀌면서 element 갯수가 1인 차원이 사라지게 된다.
이제 원하는 차원(dim)에 대해서만 squeeze를 적용해보자.
print(ft.squeeze(dim=0))
print(ft.squeeze(dim=1))
##################output###################
tensor([[0.],
[1.],
[2.]])
tensor([0., 1., 2.])
ft.squeeze(dim=0)의 경우에 텐서의 첫번째 차원은 3이므로 값의 변화가 없다.
하지만 ft.squeeze(dim=1)은 두번째 차원이 1이므로 ft.squeeze()와 같은 결과를 나타낸다.
unsqueeze 함수도 있는데, 간단히 설명 해보자면....
print(ft.unsqueeze(dim=1))
print(ft.unsqueeze(dim=1).shape)
##################output###################
tensor([[[0.]],
[[1.]],
[[2.]]])
torch.Size([3, 1, 1])
squeeze와 반대로 | ft | = (3, )을 | ft | = (3, 1)과 같이 1을 채워넣는다.
만약 print(ft.unsqueeze(-1))을 실행해보면 값이 무엇이 뜰까?
ft.unsqueeze(-1) = ft.unsqueeze(dim= -1) = ft.unsqueeze(dim=1)이므로 위의 값과 동일한 값을 반환한다.
dim = -1은 마지막 차원을 나타내는데 여기서 마지막 차원은 1과 같기 때문임. ㅇㅋ?
Concatenate : t.cat()
말 그대로 concat 해준다. 파이썬 조금이라도 써봤다면 익숙할 수 밖에 없는 함수임
x = torch.FloatTensor([[1, 2], [3, 4]])
y = torch.FloatTensor([[5, 6], [7, 8]])
print(torch.cat([x, y], dim = 0))
print(torch.cat([x, y], dim = 1))
##################output###################
tensor([[1., 2.],
[3., 4.],
[5., 6.],
[7., 8.]])
tensor([[1., 2., 5., 6.],
[3., 4., 7., 8.]])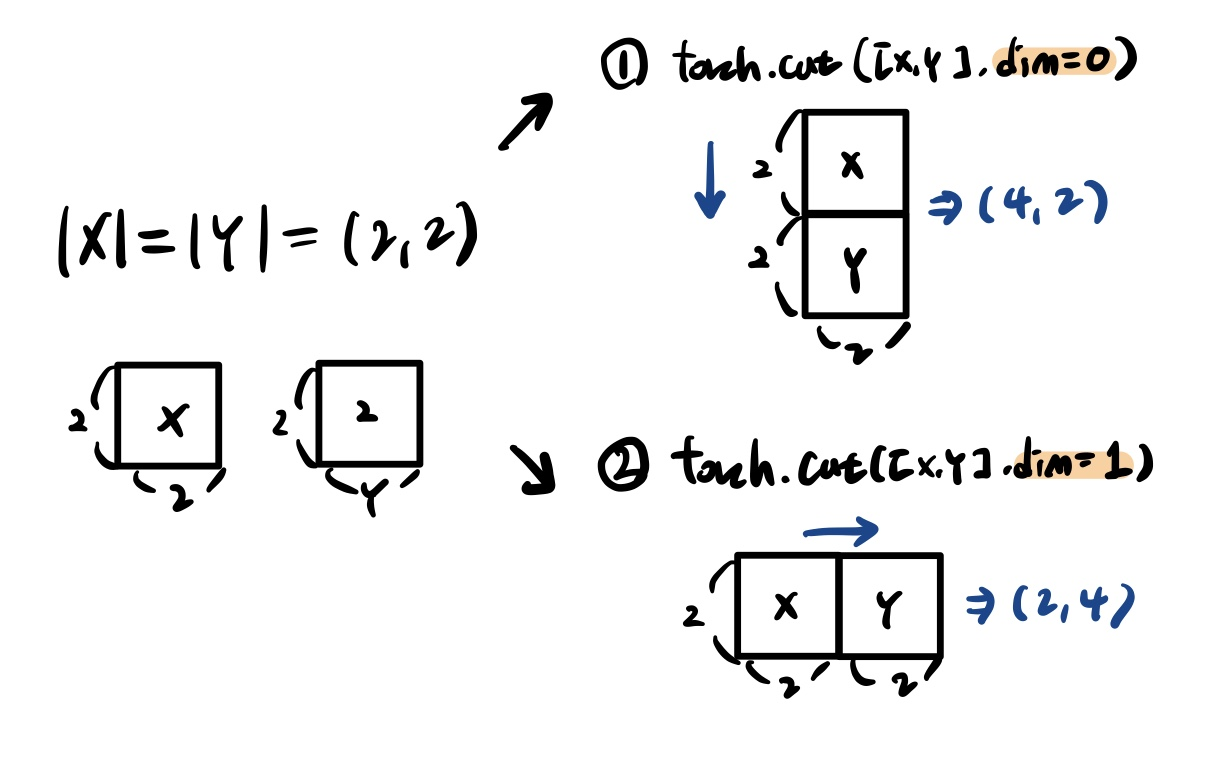
그런데 여기서...... concat보다 더 편리한 함수가 있다. 바로바로...
Stacking : t.stack()

갑자기 스쳐지나가는 자료구조 알고리즘 문해프의 기억.......... 나 올해 제법 고통스럽게 보냈구나... ...
어쨌든 stacking 함수는 concatenate 작업을 단축 시켜놓은 편리한 함수다.
stack이 뭔지 알고 있다면 어떤 함수인지 대충 감이 온다.. 말 그대로 쌓는 것이다.
x = torch.FloatTensor([1, 4])
y = torch.FloatTensor([2, 5])
z = torch.FloatTensor([3, 6])
print(torch.stack([x, y, z]))
print(torch.stack([x, y, z], dim=1))
##################output###################
tensor([[1., 4.],
[2., 5.],
[3., 6.]])
tensor([[1., 2., 3.],
[4., 5., 6.]])
dim을 따로 지정해주지 않으면 세로 방향으로 쌓는다. dim = 1로 지정을 해준다면 가로 방향으로 쌓는다.
print(torch.cat([x.unsqueeze(0), y.unsqueeze(0), z.unsqueeze(0)], dim=0))
##################output###################
tensor([[1., 4.],
[2., 5.],
[3., 6.]])
하지만 이를 torch.cat 함수를 사용해서 구현해본다면 unsqueeze를 여러번 사용하는 매우 귀찮은 작업이 필요하다. stack으로 한번에 처리 해주는게 훨씬 편하다.
Ones and Zeros : t.ones_like() & t.zeros_like()
각각 모두 1과 0으로 가득찬 tensor를 생성한다. 간단하니까 pass
In-place Operation : t.mul_()
메모리에 새롭게 tensor를 할당하지 않고 기존의 텐서에 연산된 값을 넣는 함수.
inplace=True와 유사하다고 생각하면 됨.
x = torch.FloatTensor([[1,2], [3, 4]])
print(x.mul(2.))
print(x)
print(x.mul_(2.))
print(x)
##################output###################
tensor([[2., 4.],
[6., 8.]])
tensor([[1., 2.],
[3., 4.]])
tensor([[2., 4.],
[6., 8.]])
tensor([[2., 4.],
[6., 8.]])
참고 : https://deeplearningzerotoall.github.io/season2/lec_pytorch.html감사합니다(넙죽넙죽)
모두를 위한 딥러닝 시즌 2 - PyTorch
This is PyTorch page.
deeplearningzerotoall.github.io
'Pytorch' 카테고리의 다른 글
| MNIST 분류 by softmax regression (0) | 2022.12.29 |
|---|---|
| SoftMax Regression (0) | 2022.12.29 |
| Logistic Regression (0) | 2022.12.29 |
| Mini Batch and Data Load (0) | 2022.12.29 |
| Linear Regression (0) | 2022.12.27 |