
Overfitting Problem
딥러닝에서 활성화 함수가 적용된 은닉층 개수가 많을수록 데이터 분류가 잘 된다.
하지만 훈련데이터를 과하게 학습하여 과적합이 발생될 수 있다.
예측 값과 실제 값 차이인 오차가 감소하지만 , 검증 데이터에 대해서는 오차가 증가하는 것이다.
과적합을 방지하는 방법에는 무엇이 있을까?
1. 데이터의 양을 늘린다
만약 데이터의 양이 적을 경우에는 의도적으로 기존의 데이터를 조금씩 변형하고 추가하여 데이터의 양을 늘리는 Data Augmentation을 적용하기도 한다. 이미지의 경우에 이미지를 돌리거나 노이즈를 추가하는 등의 방법으로 데이터를 증식시킴
2. 모델의 복잡도를 줄인다
ex) 선형 레이어(linear layer)의 수를 줄임
3. 가중치 규제 적용
- L1 규제 : 가중치 w들의 절대값 합계를 비용 함수에 추가
- L2 규제 : 모든 가중치 w들의 제곱합을 비용 함수에 추가
(L2 규제 사용 권장)weight_decay 매개변수를 설정하므로서 L2 규제를 적용.
model = Architecture1(10, 20, 2)
optimizer = torch.optim.Adam(model.parameters(), lr=1e-4, weight_decay=1e-5)
4. 드롭아웃
학습 과정에서 신경망의 일부를 사용하지 않는다.
학습 시 신경망이 특정 조합에 의존적이게 되는 것을 방지해주고 서로 다른 신경망을 앙상블하여 사용하는 것 같은 효과를 낸다.
class DropoutModel(torch.nn.Module):
def __init__(self):
super(DropoutModel, self).__init__()
self.layer1 = torch.nn.Linear(784, 1200)
self.dropout1 = torch.nn.Dropout(0.5) #50%의 노드를 무작위로 선택하여 사용하지 않겠다는 의미
self.layer2 = torch.nn.Linear(1200, 1200)
self.dropout2 = torch.nn.Dropout(0.5)
self.layer3 = torch.nn.Linear(1200, 10)
def forward(self, x):
x = F.relu(self.layer1(x))
x = self.dropout1(x)
x = F.relu(self.layer2(x))
x = self.dropout2(x)
return self.layer3(x)
Poor performance Problem
경사 하강법은 손실 함수 비용이 최소가 되는 지점을 찾을 때까지 기울기가 낮은 쪽으로 계속 이동시키는 과정 반복
이때 성능이 나빠지는 문제가 발생한다.

1. Batch Gradient Descent
전체 데이터셋에 대한 오류 구한 후 기울기를 한번만 계산하여 모델의 파라미터 업데이트
: 전체 훈련 데이터셋에 대하여 가중치 편미분하는 방법

한 스텝에 모든 훈련 데이터셋 사용, 학습이 오래 걸림
이 점을 개선한 방법이 바로 확률적 경사 하강법
2. 확률적 경사 하강법
임의로 선택한 데이터에 대해 기울기 계산.
적은 데이터 사용하므로 빠른 계산이 가능하다.
파라미터 변경 폭이 불안정하고 때로는 배치 하강법보다 정확도가 낮을 수 있지만 속도가 빠르다.
3. 미니 배치 경사하강법
전체 데이터셋을 미니 배치 여러개로 나누고 미니 배치 한 개마다 기울기 구한 후에 그것의 평균 기울기를 이용하여 모델 업데이트해서 학습

전체 데이터 계산하는 것보다 빠르며 확률적 경사 하강법보다 안정적이며 속도도 빠르다.
실제로 가장 많이 사용함
class CustomDataSet(DataSet):
def __init__(self):
self.x_data = [[1,2,3], [4,5,6], [7,8,9]]
self.y_data = [[12], [18], [11]]
def __len__(self):
return len(self, x_data)
def __getitem__(self, idx):
x = torch.FloatTensor(self.x_data[idx])
y = torch.FloatTensor(self.y_data[idx])
return x, y
dataset = CustomDataSet()
dataloader = DataLoader(
dataset, batch_size=2, shuffle=True)
기울기 소실과 폭주 막는 방법?
1. ReLU 함수나 Leacky ReLU함수 사용
2. 가중치 초기화 weight initialization
- He initialization
정규 분포와 균등 분포 두가지 경우로 나뉘는데, 다음 층의 뉴런 수를 반영하지 않는다.
ReLU 함수 사용시 이 초기화 방법이 더 효율적
보통 ReLU + He 초기화 방법이 보편적.
*내부 공변량 변화 (Internal Covariant Shift)
학습 과정에서 층 별로 입력 데이터 분포가 달라지는 현상
각 계층에서 입력으로 feature를 받게 되고 그 feature는 convolution이나 위와 같이 fully connected 연산을 거친 뒤 activation function을 적용하게 됨
이전 층들의 학습에 의해 이전 층의 가중치 값이 바뀌게 되면, 현재 층에 전달되는 입력 데이터의 분포가 현재 층이 학습했던 시점의 분포와 차이가 발생.
Batch 단위로 학습하게 되면 Batch 단위 간에 데이터 분포의 차이 발생. = Batch 간의 데이터가 상이
3. 배치 정규화 Batch Normalization
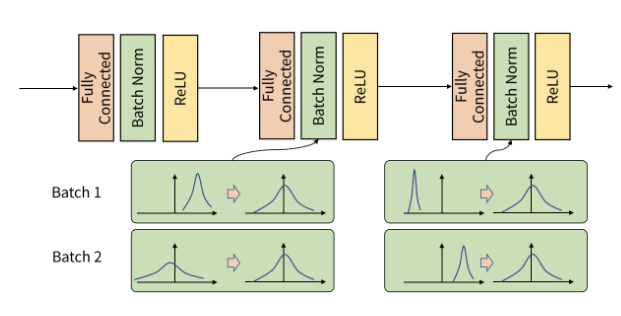
인공 신경망의 각 층에 들어가는 입력을 평균과 분산으로 정규화
batch 단위나 층에 따라서 입력 값의 분포가 모두 다르다. 하지만 정규화를 통해서 분포를 zero mean gaussian 형태로 만든다. 그러면 평균은 0, 표준 편차는 1로 데이터 분포 조정 가능.
학습 단계의 BN 구하기 위해서 사용된 평균과 분산 구할 때에는 배치 별로 계산되어야 의미가 있음.
그래야 각 배치들이 표준 정규 분포를 각각 따르게 됨. 이때도 bias(B)로 나눠준다.
학습 단계에서 모든 feature에 정규화 해주면 정규화로 인하여 feature가 동일한 스케일이 되어 학습률 결정에 유리해짐.
batch normalization은 활성화 함수 앞에 적용된다.
참고
https://gaussian37.github.io/dl-concept-batchnorm/
배치 정규화(Batch Normalization)
gaussian37's blog
gaussian37.github.io
'Pytorch' 카테고리의 다른 글
| 퍼셉트론과 딥러닝, 활성화 함수, 손실 함수, 순전파와 역전파 (0) | 2023.01.02 |
|---|---|
| MNIST 분류 by softmax regression (0) | 2022.12.29 |
| SoftMax Regression (0) | 2022.12.29 |
| Logistic Regression (0) | 2022.12.29 |
| Mini Batch and Data Load (0) | 2022.12.29 |